|
DFT-EFE
|

|
|
DFT-EFE
|
|
Functions | |
| void | setupELPAHandleParameters (const utils::mpi::MPIComm &mpi_communicator, utils::mpi::MPIComm &processGridCommunicatorActive, const std::shared_ptr< const ProcessGrid > &processGrid, const size_type na, const size_type nev, const size_type blockSize, elpa_t &elpaHandle, const bool useELPADeviceKernel=false) |
| Contains internal functions used in linearAlgebra. More... | |
| void | createProcessGridSquareMatrix (const utils::mpi::MPIComm &mpi_communicator, const size_type size, std::shared_ptr< const ProcessGrid > &processGrid, const size_type scalapackParalProcs, const bool useELPA, const bool useOnlyThumbRule=false) |
| Wrapper function to create a two dimensional processor grid for a square matrix in ScaLAPACKMatrix storage format. More... | |
| void | createProcessGridRectangularMatrix (const utils::mpi::MPIComm &mpi_communicator, const size_type sizeRows, const size_type sizeColumns, std::shared_ptr< const ProcessGrid > &processGrid) |
| Wrapper function to create a two dimensional processor grid for a rectangular matrix in ScaLAPACKMatrix storage format. More... | |
| template<typename T > | |
| void | createGlobalToLocalIdMapsScaLAPACKMat (const std::shared_ptr< const ProcessGrid > &processGrid, const ScaLAPACKMatrix< T > &mat, std::unordered_map< size_type, size_type > &globalToLocalRowIdMap, std::unordered_map< size_type, size_type > &globalToLocalColumnIdMap) |
| Creates global row/column id to local row/column ids for ScaLAPACKMatrix. More... | |
| template<typename T > | |
| void | scaleScaLAPACKMat (const std::shared_ptr< const ProcessGrid > &processGrid, ScaLAPACKMatrix< T > &mat, const T scalar) |
| scale a ScaLAPACKMat with a scalar More... | |
| template<typename T > | |
| void | fillParallelOverlapMatrix (const T *X, const size_type XLocalSize, const size_type numberVectors, const std::shared_ptr< const ProcessGrid > &processGrid, const utils::mpi::MPIComm &mpiComm, const size_type wfcBlockSize, ScaLAPACKMatrix< T > &overlapMatPar) |
| Computes Sc=X^{T}*Xc and stores in a parallel ScaLAPACK matrix. X^{T} is the subspaceVectorsArray stored in the column major format (N x M). Sc is the overlapMatPar. More... | |
| template<typename ValueType , typename utils::MemorySpace memorySpace> | |
| void | subspaceRotation (ValueType *X, const size_type M, const size_type N, const std::shared_ptr< const ProcessGrid > &processGrid, const utils::mpi::MPIComm &mpiCommDomain, LinAlgOpContext< memorySpace > &linAlgOpContext, const ScaLAPACKMatrix< ValueType > &rotationMatPar, const size_type subspaceRotDofsBlockSize, const size_type wfcBlockSize, const bool rotationMatTranspose=false, const bool isRotationMatLowerTria=false, const bool allowFullCPUMemSubspaceRot=(memorySpace==utils::MemorySpace::DEVICE ? true :false)) |
| Computes X^{T}=Q*X^{T} inplace. X^{T} is the subspaceVectorsArray stored in the column major format (N x M). Q is rotationMatPar (N x N). More... | |
| void dftefe::linearAlgebra::elpaScalaOpInternal::createGlobalToLocalIdMapsScaLAPACKMat | ( | const std::shared_ptr< const ProcessGrid > & | processGrid, |
| const ScaLAPACKMatrix< T > & | mat, | ||
| std::unordered_map< size_type, size_type > & | globalToLocalRowIdMap, | ||
| std::unordered_map< size_type, size_type > & | globalToLocalColumnIdMap | ||
| ) |
Creates global row/column id to local row/column ids for ScaLAPACKMatrix.
| void dftefe::linearAlgebra::elpaScalaOpInternal::createProcessGridRectangularMatrix | ( | const utils::mpi::MPIComm & | mpi_communicator, |
| const size_type | sizeRows, | ||
| const size_type | sizeColumns, | ||
| std::shared_ptr< const ProcessGrid > & | processGrid | ||
| ) |
Wrapper function to create a two dimensional processor grid for a rectangular matrix in ScaLAPACKMatrix storage format.

| void dftefe::linearAlgebra::elpaScalaOpInternal::createProcessGridSquareMatrix | ( | const utils::mpi::MPIComm & | mpi_communicator, |
| const size_type | size, | ||
| std::shared_ptr< const ProcessGrid > & | processGrid, | ||
| const size_type | scalapackParalProcs, | ||
| const bool | useELPA, | ||
| const bool | useOnlyThumbRule = false |
||
| ) |
Wrapper function to create a two dimensional processor grid for a square matrix in ScaLAPACKMatrix storage format.


| void dftefe::linearAlgebra::elpaScalaOpInternal::fillParallelOverlapMatrix | ( | const T * | X, |
| const size_type | XLocalSize, | ||
| const size_type | numberVectors, | ||
| const std::shared_ptr< const ProcessGrid > & | processGrid, | ||
| const utils::mpi::MPIComm & | mpiComm, | ||
| const size_type | wfcBlockSize, | ||
| ScaLAPACKMatrix< T > & | overlapMatPar | ||
| ) |
Computes Sc=X^{T}*Xc and stores in a parallel ScaLAPACK matrix. X^{T} is the subspaceVectorsArray stored in the column major format (N x M). Sc is the overlapMatPar.
The overlap matrix computation and filling is done in a blocked approach which avoids creation of full serial overlap matrix memory, and also avoids creation of another full X memory.
| void dftefe::linearAlgebra::elpaScalaOpInternal::scaleScaLAPACKMat | ( | const std::shared_ptr< const ProcessGrid > & | processGrid, |
| ScaLAPACKMatrix< T > & | mat, | ||
| const T | scalar | ||
| ) |
scale a ScaLAPACKMat with a scalar
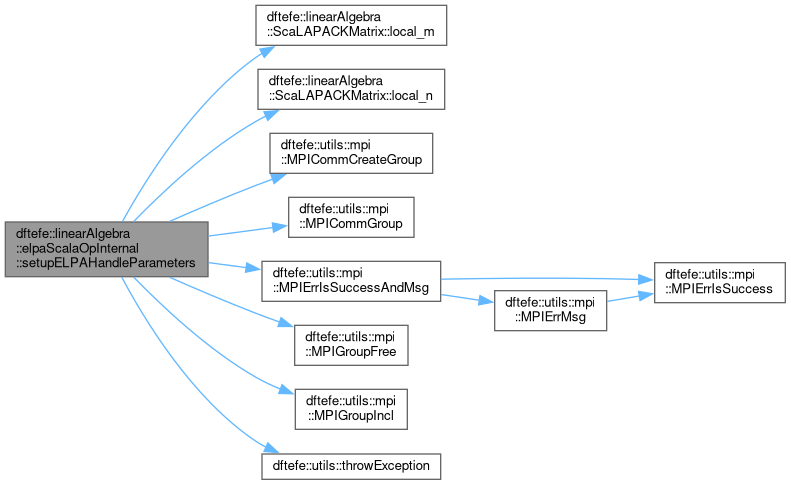
| void dftefe::linearAlgebra::elpaScalaOpInternal::setupELPAHandleParameters | ( | const utils::mpi::MPIComm & | mpi_communicator, |
| utils::mpi::MPIComm & | processGridCommunicatorActive, | ||
| const std::shared_ptr< const ProcessGrid > & | processGrid, | ||
| const size_type | na, | ||
| const size_type | nev, | ||
| const size_type | blockSize, | ||
| elpa_t & | elpaHandle, | ||
| const bool | useELPADeviceKernel = false |
||
| ) |
Contains internal functions used in linearAlgebra.
setup ELPA parameters.

| void dftefe::linearAlgebra::elpaScalaOpInternal::subspaceRotation | ( | ValueType * | X, |
| const size_type | M, | ||
| const size_type | N, | ||
| const std::shared_ptr< const ProcessGrid > & | processGrid, | ||
| const utils::mpi::MPIComm & | mpiCommDomain, | ||
| LinAlgOpContext< memorySpace > & | linAlgOpContext, | ||
| const ScaLAPACKMatrix< ValueType > & | rotationMatPar, | ||
| const size_type | subspaceRotDofsBlockSize, | ||
| const size_type | wfcBlockSize, | ||
| const bool | rotationMatTranspose = false, |
||
| const bool | isRotationMatLowerTria = false, |
||
| const bool | allowFullCPUMemSubspaceRot = (memorySpace == utils::MemorySpace::DEVICE ? true : false) |
||
| ) |
Computes X^{T}=Q*X^{T} inplace. X^{T} is the subspaceVectorsArray stored in the column major format (N x M). Q is rotationMatPar (N x N).
The subspace rotation inside this function is done in a blocked approach which avoids creation of full serial rotation matrix memory, and also avoids creation of another full subspaceVectorsArray memory. subspaceVectorsArrayLocalSize=N*M